更新时间:2023-02-06 07:18:14浏览次数:411+次
本文介绍如何在Linux系统上安装和使用Teseract OCR 5的方法,当前可从源代码或者使用Docker/Podman容器来安装,将以Rocky Linux 8、AlmaLinux 8发行版做示例。
安装Teseract OCR 5
1、从源代码安装
我们将首先安装从源文件构建Teseract OCR 5所需的软件包:
sudo yum install git automake make autoconf libtool clang gcc-c++.x86_64
需要更多的leptonica依赖性:
sudo yum install zlib zlib-devel libjpeg libjpeg-devel libwebp libwebp-devel libtiff libtiff-devel libpng libpng-devel
将可执行文件移动到您的路径:
cd /usr/local/lib
sudo cp /usr/lib64/libjpeg.so.62 .
sudo cp /usr/lib64/libwebp.so.7 .
sudo cp /usr/lib64/libtiff.so.5 .
sudo cp /usr/lib64/libpng16.so.16 .
从源代码编译Leptonica。首先从git克隆它,如下所示:
cd ~
git clone https://github.com/DanBloomberg/leptonica.git --depth 1
cd leptonica
现在编译并安装Leptonica:
./autogen.sh
./configure --prefix=/usr/local --disable-shared --enable-static --with-zlib --with-jpeg --with-libwebp --with-libtiff --with-libpng --disable-dependency-tracking
make
sudo make install
sudo ldconfig
一旦安装了Leptonica,我们将继续从Github下载Teseract OCR 5。您也可以使用Wget:
cd ~
VER=$(curl -s https://api.github.com/repos/tesseract-ocr/tesseract/releases/latest|grep tag_name | cut -d '"' -f 4)
wget https://github.com/tesseract-ocr/tesseract/archive/refs/tags/$VER.tar.gz -O tesseract-5.tar.gz
提取存档:
tar zxvf tesseract-5.tar.gz
导航到提取的目录:
cd tesseract-*/
现在编译Teseract OCR 5:
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig
./autogen.sh
./configure --prefix=/usr/local --disable-shared --enable-static --with-extra-libraries=/usr/local/lib/ --with-extra-includes=/usr/local/lib/
make
使用以下命令安装Teseract OCR 5:
sudo make install
sudo ldconfig
下面加载细分语言。
通过创建语言路径加载tesseract语言:
mkdir -p /tess/traineddata
通过将以下行添加到~/.bashrc来导出Teseract路径:
export TESSDATA_PREFIX=/home/$USER/tess/traineddata
您可以用系统上的确切用户名替换$USER。
源配置文件:
source ~/.bashrc
现在将Github tessdata上可用的数据添加到路径中,地址在https://github.com/tesseract-ocr/tessdata:
cd $TESSDATA_PREFIX
wget https://github.com/tesseract-ocr/tessdata/raw/main/eng.traineddata
wget https://github.com/tesseract-ocr/tessdata/raw/main/fra.traineddata
2、使用Docker/Podman容器安装
我假设您的系统上已经安装了Docker/Podman引擎。可参考如何在Ubuntu 22.04系统上安装Docker CE:https://www.hmxthome.com/linux/4941.html
可以使用以下命令安装Podman:
sudo yum install podman
安装首选容器引擎后,创建Teseract OCR 5 docker文件:
vim Dockerfile
在文件中,添加以下行:
FROM ubuntu:20.04
RUN apt-get update -y
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get install -y gnupg apt-transport-https apt-utils wget
RUN echo "deb https://notesalexp.org/tesseract-ocr5/focal/ focal main" \
|tee /etc/apt/sources.list.d/notesalexp.list > /dev/null
RUN wget -O - https://notesalexp.org/debian/alexp_key.asc | apt-key add -
RUN apt-get update -y
RUN apt-get install tesseract-ocr -y
RUN apt install imagemagick -y
ENTRYPOINT ["tesseract"]
RUN tesseract -v
保存文件并构建Tesseract 5 image:
$ docker build . -t tesseract:5
##或
$ podman build . -t tesseract:5
一旦生成,您将看到以下信息:
Removing intermediate container a9ecd5a7810f
---> e1f76f250bc1
Step 10/11 : ENTRYPOINT ["tesseract"]
---> Running in 1886dfbcfd5e
Removing intermediate container 1886dfbcfd5e
---> 30afc1531eb9
Step 11/11 : RUN tesseract -v
---> Running in 598972cbd362
tesseract 5.0.1
leptonica-1.79.0
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 2.0.3) : libpng 1.6.37 : libtiff 4.1.0 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.1
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found OpenMP 201511
Found libarchive 3.4.0 zlib/1.2.11 liblzma/5.2.4 bz2lib/1.0.8 liblz4/1.9.2 libzstd/1.4.4
Found libcurl/7.68.0 OpenSSL/1.1.1f zlib/1.2.11 brotli/1.0.7 libidn2/2.2.0 libpsl/0.21.0 (+libidn2/2.2.0) libssh/0.9.3/openssl/zlib nghttp2/1.40.0 librtmp/2.3
Removing intermediate container 598972cbd362
---> 35f8f89ea444
Successfully built 35f8f89ea444
Successfully tagged tesseract:5
检查image:
##对于Docker
$ docker images
tesseract 5 35f8f89ea444 14 seconds ago 302MB
##对于Podman
$ podman images
localhost/tesseract 5 f92efe531f58 2 minutes ago 309MB
使用Tesseract image,现在可以使用语法运行Teseract:
##对于Docker
docker run --rm -v /path/to/image/:/tmp/:z tesseract:5 /tmp/img.jpg stdout
##对于Podman
podman run --rm -v /path/to/image/:/tmp/:z localhost/tesseract:5 /tmp/img.jpg stdout
在上述命令中:
–rm,在运行上述命令后删除conatiner。
–v,指定卷,其中/path/to/image/作为要装载在服务器的/tmp/上的本地路径,/tmp/img.jpg是装载的本地路径的映像文件的确切位置。
tesseract:5,是创建的conatiner image。
z,修改selinux标签。它表示绑定装载内容在多个容器之间共享。
使用Teseract OCR 5
一旦安装了Teseract OCR 5,您现在可以开始从扫描的文档或图像中提取文本。
要将图像转换为文本文件,使用的语法如下:
tesseract <image_name> <output file_name>
例如,将图像转换为文本文件时,命令为:
tesseract image.png new
输出将是图像文件-image.png的文本文件-new。
对于Docker/Podman,假设图像文件image.png位于/home/thor/Desktop/image.png,命令如下:
##对于Docker
docker run --rm -v /home/thor/Desktop/:/tmp/:z tesseract:5 /tmp/image.png stdout
##对于Podman
podman run --rm -v /home/thor/Desktop/:/tmp/:z localhost/tesseract:5 /tmp/image.png stdout
或者,在导航到带有图像文件的目录后,按如下方式缩短命令(Podman示例):
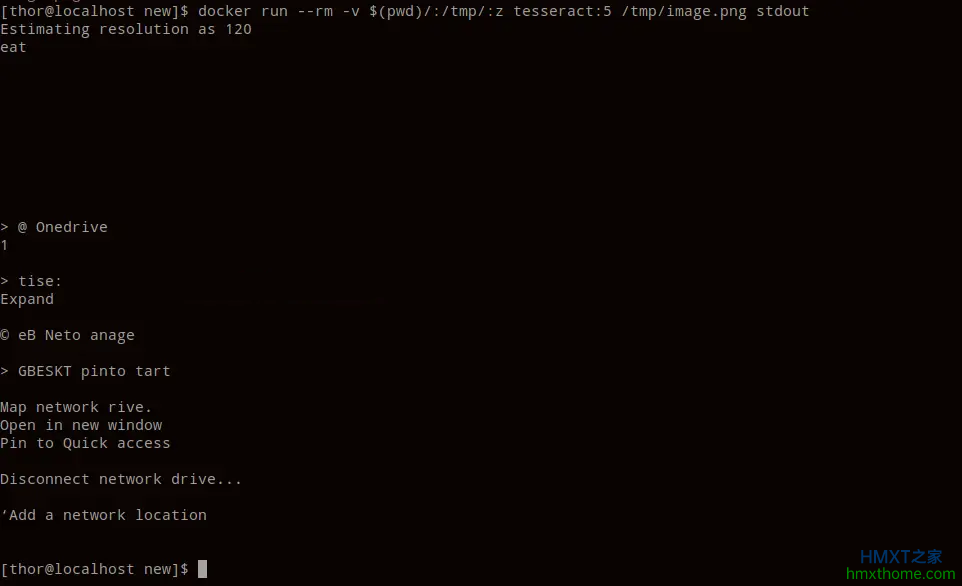
podman run --rm -v $(pwd)/:/tmp/:z localhost/tesseract:5 /tmp/image.png stdout
这是目录中image.png的文本输出截图:
您还可以将上面的输出保存到文件new.txt中,如下所示:
tesseract image.png new
Docker示例:
docker run --rm -v $(pwd)/:/tmp/:z tesseract:5 /tmp/image.png /tmp/new
或以下PDF文件(new.pdf):
tesseract image.png new pdf
docker示例:
docker run --rm -v $(pwd)/:/tmp/:z tesseract:5 /tmp/image.png /tmp/new pdf
下面是指定语言的方法。
在使用Teseract OCR时,可以使用-l标志指定要使用的语言。例如,使用Czech:
tesseract image.png new -l ces
您还可以指定多种语言:
tesseract image.png new -l ces+eng
结论
通过本文,我们能够成功地在Linux系统上安装并使用Teseract OCR 5。现在,您可以轻松地从图像和扫描文档中提取文本了。
相关资讯